AWS Elastic MapReduce (EMR)
Lo que vamos a hacer es usar las capacidad de Amazon EMR (Elastic Map Reduce) para ejecutar nuestro contador de palabras sin tener que preocuparnos de instalaciones de clusters.NOTA IMPORTANTE:
Amazon EMR NO es gratuito y no entra dentro de las posibilidades de la AWS Free Tier por lo que realizar este tutorial, aunque cuesta menos de 1€, no es gratuito. Al final del todo pondré una captura de pantalla del coste total que fueron 0.21€
Creando un bucket S3 y subiendo los archivos
Lo primero que tendremos que hacer es crear un bucket S3 para subir archivos dentro. S3 es un sistema de almacenamiento en la nube que, con la AWS Free tier nos otorga 5gb de almacenamiento gratuito. Habrá que meterse en la cuenta de AWS y seleccionar, dentro de los servicios, el S3:

Una vez en la ventana de S3, hay que hacer click en "Create bucket":

Y darle un nombre al bucket:
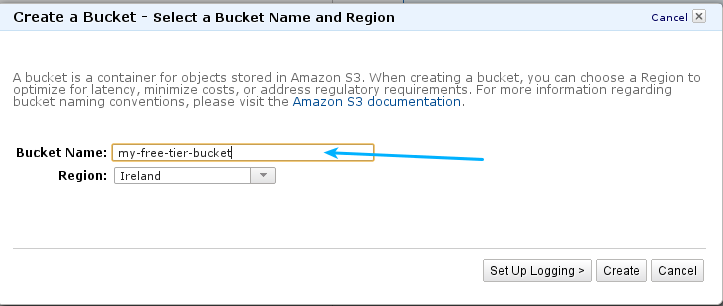
Subir los archivos al bucket
Ahora que ya tenemos un bucket de almacenamiento, hay que seleccionar "Actions-Upload" para seleccionar los dos archivos que queremos subir, uno de ellos el fichero del que queremos contar las palabras y otro el JAR que contiene el Wordcount que escribimos en el tutorial de



Creando el cluster
Paso 1: Cluster configuration
Ahora, seleccionamos el servicio de Amazon EMR de la selección de servicios. En la ventana que nos aparece hay que seleccionar "Create cluster":
 |
| Primer paso para la creación de un cluster |
Atención al botón de "Configure sample application". Como se puede intuir, este botón nos abre otra ventana para poder ejecutar el cluster con algunos trabajos de ejemplo (entre ellos el propio contador de palabras). Como lo que queremos es aprender como se hace, vamos a evitar usar el botón.
Paso 2: Software configuration
Una vez le hemos dado un nombre al cluster y hemos seleccionado una ubicación en nuestro S3 para el almacenamiento de los logs, pasamos a seleccionar la AMI y versión de Hadoop a usar:

Vamos a usar la version 2.4.2 de la AMI con hadoop 1.0.3. Como podeis ver, también nos da la opción de instalar Hive o Pig. Para los propósitos de este tutorial no será necesario pero no pasa nada si se instalan.
Paso 3: Hardware configuration
Pasamos al siguiente paso que va a ser la configuración de acceso. Para los propósitos de este tutorial vamos a usar una instancia small para el contenedor del Namenode, el SecondaryNamenode y el JobTracker y 2 instancias small con un DataNode y un TaskTracker cada una. Por último, aunque no es estrictamente necesario, hay que seleccionar una clave PEM para el acceso a las máquinas. A nosotros no nos va a hacer falta ya que sólo vamos a arrancar las máquinas para hacer el conteo y se van a parar al finalizar.
Paso 4: Steps
El último de los pasos para la creación del cluster son los "Steps", que son los trabajos a realizar. Nuestro step va a ser ejecutar el Wordcount que vendrá configurado automáticamente (lo seleccionamos en un paso anterior cuando abrimos el cuadro de diálogo de "Configure Sample Application").


Asegurarse de tener elegido "Terminate cluster" en "Action on Failure"

Navegar y seleccionar el archivo a contar palabras
Una vez tengamos todo, seleccionamos "Select" dentro de la ventana de "Select S3 Folder" y "Save" en la ventana de "Add Step". Ya está el trabajo y el cluster configurado para ejecutar.
Finalmente hacemos click en "Create cluster" y nuestro MapReduce ya estará corriendo.
Algunos aspectos básicos de AWS EMR: Si por alguna circunstancia hay un error de configuración dentro del cluster, no se cargará ningún gasto a vuestra cuenta. Sólo se carga cuando el MapReduce consigue iniciarse, en cuyo caso, si hay error; sí que habrá un pequeño cargo.
Resultado
Los resultados de la ejecución los podremos ver en nuestro S3, dentro de la carpeta que venía configurada en el "Output S3 folder" dentro de la ventana de "Add Step". En la siguiente imagen podéis ver en el resultado del Wordcount dentro del bucket S3:

Notas finales
Como se puede apreciar, la ejecución de una tarea EMR en AWS es realmente sencilla, mucho mas que crear nuestro propio cluster, nuestro propio MapReduce, etc. Esto demuestra las tremendas posibilidades de usar AWS EMR para la ejecución de docenas o cientos de "Workers" a sólo unos clicks de ratón. A mi, personalmente, me dejó impresionado, sobre todo teniendo en cuenta que también se pueden ejecutar scripts Pig y Hive con la misma facilidad.
2 comentarios:
Hola, me parece muy interesante el tutorial que presentas, una duda que me surgio es como interpretar los resultados, cual de los tres archivos es el resultado?
como interpretar cuales son los Map y Reduce?
Gracias.,
Hola,
Generalmente, los resultados del Map son procesados internamente y no son volcados a disco (básicamente porque estamos tratando con muchas cantidades de datos y lo que menos queremos es duplicar su tamaño).
Si los quisieras por separado tendrías que hacer un JAR que fuera tu Map y otro que tuviera también el reducer.
¡Saludos!
Publicar un comentario